
本日の自動収集パイプラインからのレポートでは、AIモデルの急速な能力向上に伴う「安全性と法的責任」の明確化、そして産業現場における「データ統合」の重要性が大きく取り上げられている。
モデルが想像を超えるスピードで賢くなる中で、我々エンジニアは「AIに何をさせ、どこでAIを使うのをやめるか」という、一歩踏み込んだ設計思想を求められている。
「利用者の無邪気さ」を前提としたルール設計
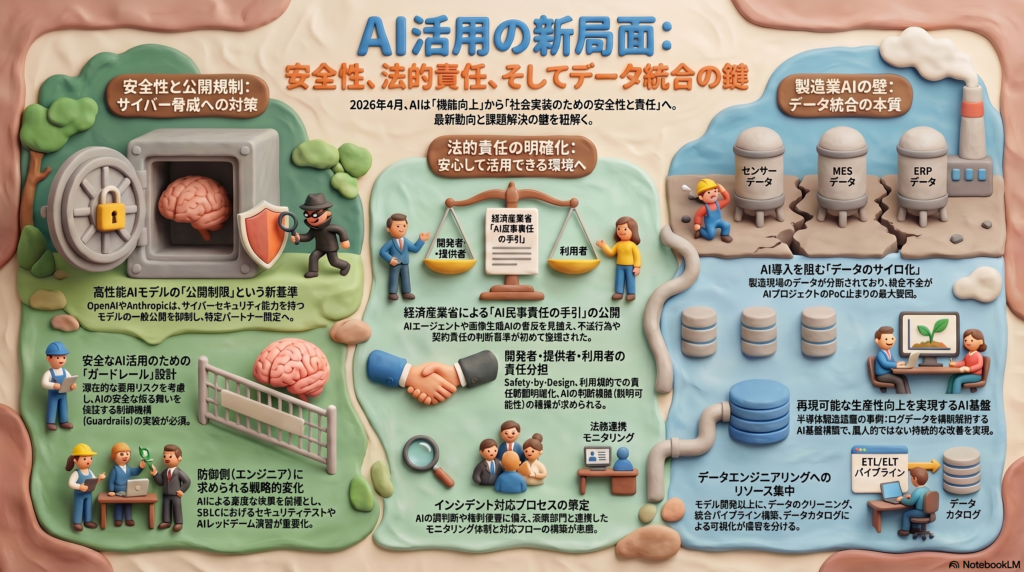
経済産業省がAI活用時の法的責任に関する手引を公開するなど、開発者・提供者・利用者の責任分担を明確にする動きが加速している。モデルに倫理を埋め込むのは人間であり、設計段階からルールを組み込む「Safety-by-Design」の重要性は言うまでもない。
しかし、現場でシステムを使う利用者の多くは、責任の所在よりも「結果」を最優先する。利用者が「AIが出した結果だから自分には関係ない」と無邪気に責任を回避するリスクは常に存在する。だからこそ、利用者のリテラシーに依存するのではなく、システム側で逸脱を許さないガードレールを物理的に(コードとして)実装しておくことが、開発者にとっての最大の防御策となる。
スマートファクトリーが陥る「リアルタイムの呪縛」
昨今、製造業のスマートファクトリー化において「データの鮮度」は至上命題とされ、異常検知や予知保全の領域では、こぞって「リアルタイムなAI分析」が求められている。しかし、ここには世間が陥りがちな「リアルタイムの呪縛」と「AIへの万能感」が潜んでいる。
例えば、現場のIoTセンサー(OT)から送られてくる高速なデータと、別タイミングで更新される基幹システム(IT)のログをAIに流し込む際、データがシステムに到着するタイミングには必ずズレ(ラグ)が生じる。これを無理に「完全リアルタイム」で処理しようとすると、AIはズレたデータ同士を強引に結びつけ、的外れな因果関係を学習してしまう。これが、現場でAIの誤検知が多発する原因の一つだ。
世間(経営層やベンダー)はAIを「曖昧なデータでも空気を読んで解釈してくれる魔法の箱」と錯覚しがちだ。しかし、データ基盤という観点においては、AIも数あるシステムツールの一つに過ぎない。AI自体がデータの物理的なズレを魔法のように補正してくれるわけではないのだ。
だからこそ、AIに過度な万能感を求めるのではなく、他のツールと同列に限界を理解し、「このツール(AI)に正しい仕事をさせるには、前段でどうデータを整えるべきか」を冷静に検討する必要がある。「データには必ずズレが生じる」というシステム特性を理解し、あえて数秒間のバッファ(遅延)を設けてでも、データの発生時刻を正確に同期させてからAIに渡すこと。中途半端な「今」を無理にリアルタイム分析させるより、数秒遅れてでも「完全に整合性のとれた状態」を分析させる方が、結果的に推論の信頼性は圧倒的に高くなるのだ。
「推論」の次は「決定論的プログラム」への置き換え
今回の事例を深掘りする中で至った一つの結論がある。それは、「AIを使って高速にプロセス(ルール)を決定できたら、決まった部分はプログラムに置き換えていくべきではないか」という視点だ。
AI(LLMなど)は、複雑でファジーな状況から最適解を見出す「推論」や「検証」には極めて強力だ。しかし、一度最適なロジックや分岐条件が定まったのであれば、それをいつまでもAIに判断させ続ける必要はない。
- AIの役割: 膨大なデータから最適な「ルール」や「プロセス」を発見・決定する。
- プログラムの役割: 定まったルールを、決定論的(100%の再現性)に、高速かつ低コストで実行する。
決定論的に書けるロジックは、わざわざファジーさを孕むAIを通さず、if-elseやスイッチングといった堅牢なコードに落とし込む。これこそが、システムの確実性とコストパフォーマンスを両立させる、AI時代の新しいシステムアーキテクチャの姿ではないだろうか。
まとめ:AIは「プロセス開発」の触媒である
AIは、完成された永続的なエンジンである必要はない。むしろ、複雑な事象を整理し、最適なプロセスを定義するための「強力な触媒」として使い倒すべきだ。
AIでプロセスを決め、決まったことはAIを使わずに動かす。この「脱AI化」のタイミングを見極めることこそが、これからのシステム設計者に求められる高度なバランス感覚である。
